前言
不知從何時開始,我沈迷於各種生產力工具、提高生產力的內容,可能是為了緩解我的知識焦慮、也可能這是一種比較沒有罪惡感地拖延方式。 曾經用 Smart Connection, Copilot 插件幫我做筆記內容檢索,但因為 OpenAI 免費試用到期了,作為一個免費仔當然不可能課金(主要是我很窮),所以一直有想要把本地 LLM 弄起來。但因為拖延症跟對技術的 PTSD,遲遲沒有開始。直到前幾天在推特看到有人分享 Ollama + Obsidian 的玩法,才萌生了來搞一下的念頭。又發現用這個工具技術門檻不高,於是有了這篇文章。
安裝步驟
Step.1 下載安裝 Ollama
- 下載 Ollama 對應系統的,因為我的電腦是 mac 所以使用 macOS 版本
- Download Ollama on macOS
Step.2 安裝語言模型
- 安裝並開啟,跟著他的步驟執行安裝模型
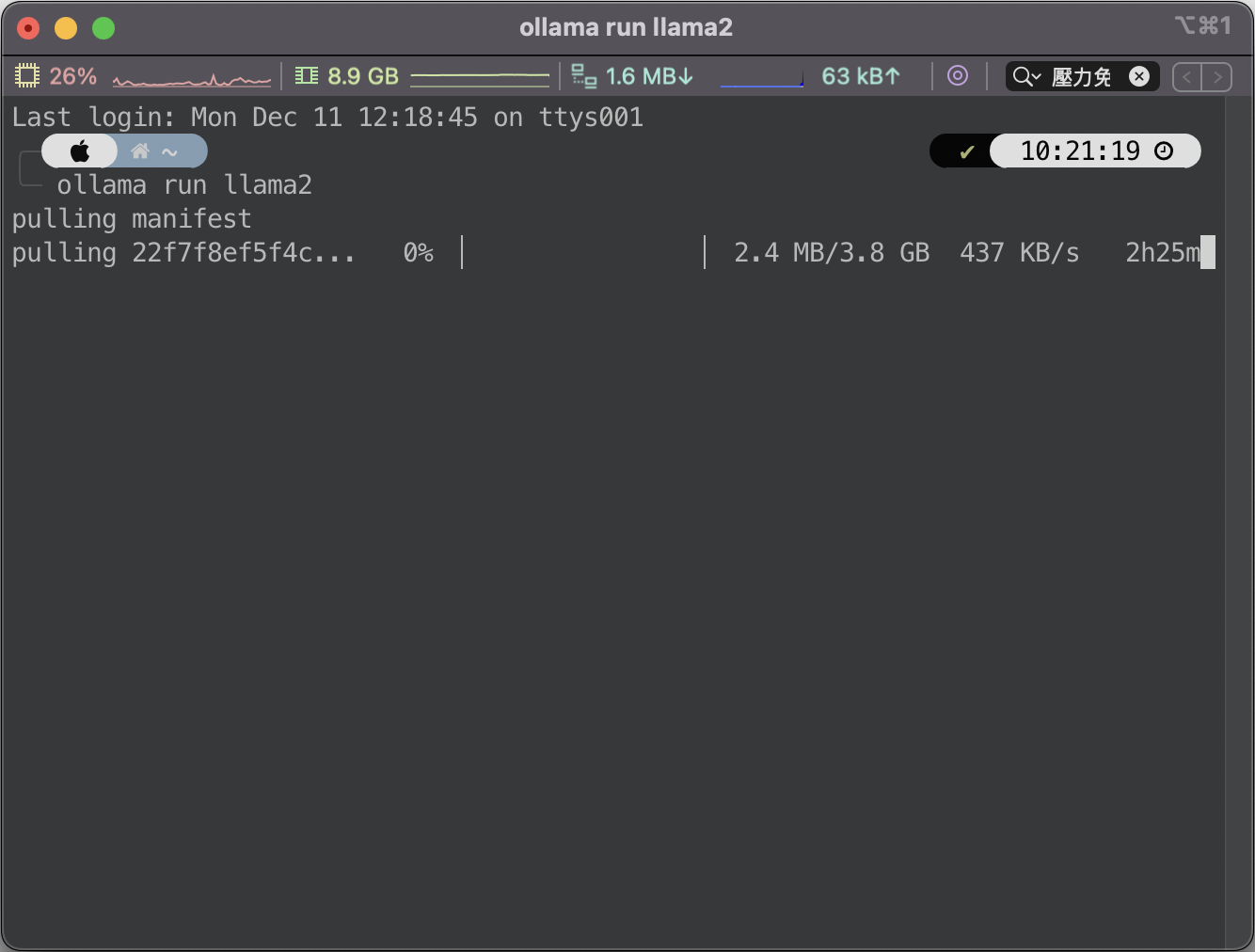
- 在終端機上執行上圖指令,安裝 llama2 時會需要
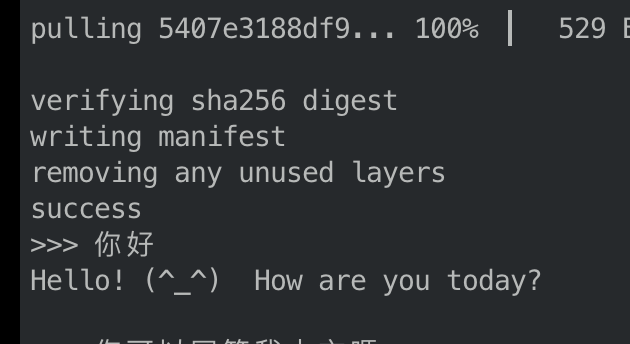
億一點點時間下載模型 - 安裝完成之後就能跟他聊天了,似乎只能回答英文,但他是看得懂中文的
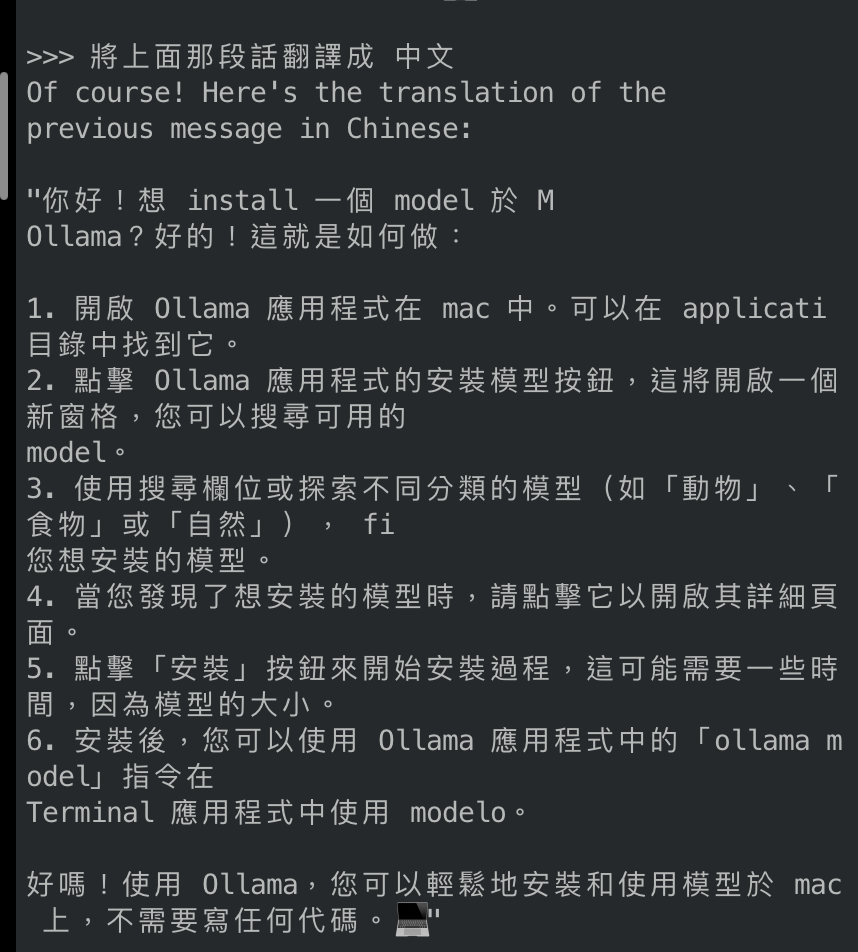
- 似乎是可以回答中文的,但是翻譯能力沒有很好,回答問題也會優先用英文回答
相關連結
Ollama GitHub:GitHub - jmorganca/ollama: Get up and running with Llama 2 and other large language models locally Ollama 支援模型:library dolphin-mixtral(經調教沒有審查機制的模型):Tags · dolphin-mixtral
一些 Ollama 使用
CLI (llama2 為例)
- 執行模型:
ollama run llama2 - 更新本地模型:
ollama pull llama2 - 移除本地模型:
ollama rm llama2 - 列出本機模型:
ollama list
搭配使用更對味
Obsidian
Obsidian Ollama Plugin
- Obsidian Ollama plugin
- 安裝完基本上就可以直接使用
- 功能類似 Notion 的 AI,但不需要擔心你的敏感資訊上傳去別人的伺服器
- 使用心得:很難用,模型都答非所問,可能我的電腦裝不起太屌的模型
Obsidian BMO Chatbot Plugin
- Obsidian BMO Chatbot plugin
- 需要做一些設定
- 在 OLLAMA REST API URL 貼上
http://127.0.0.1:11435(如果有改過可能不一樣) - 繞過 CORS 政策,運行 Ollama 伺服器:
OLLAMA_ORIGINS=* OLLAMA_HOST=127.0.0.1:11435 ollama serve - 預設是 chatGPT 模型,所以要在聊天介面輸入指令
\model [model_name]切換成本地的模型 \help看更多操作(例如:以這則筆記當成參考)- 使用心得 todo
Obsidian-ai-research-assistant
Logseq
- [Logseq Ollama plugin](https://github.com/omagdy7/ollama-logseq
- 也是一個生成內容的插件,但是是在 Logseq 上
- 列出來是因為我有在用 Logseq
Raycast
- Raycast extension
- 一個方便好用手不用離開鍵盤的東西
Llama Coder
- GitHub - ex3ndr/llama-coder: Replace Copilot with a more powerful and local AI
- 一個替代微軟 copilot 的本地 LLM,也是個免費仔好朋友
- 自動補齊程式碼
其他紀錄
- 除了 Ollama,要自己 host LLM 也可以使用 LocalAI
- 對於 Obsidian 來說有個知名的插件 Copilot 就可以用 LocalAI
Ref.
- 现在最火的开源大语言模型当属 mixtral-8x7 了,已经…
- 一直感觉很多笔记软件的AI功能设计偏了。。最近用Obsidian+AI插件,打造了…
- 写个如何用 Ollama 在 Mac 本地跑 LLM,并且用在 Obsidian 上处理…
- GitHub - jmorganca/ollama: Get up and running with Llama 2 and other large language models locally
- GitHub - longy2k/obsidian-bmo-chatbot: Generate and brainstorm ideas while creating your notes using Large Language Models (LLMs) such as OpenAI’s “gpt-3.5-turbo” and “gpt-4” for Obsidian.